Clustering d'images
Dans cet article, nous allons explorer un projet fascinant de transformation numérique impliquant une collection massive de 37,000 images, allant des années 1900 jusqu'à aujourd'hui. Ce projet combine des techniques avancées de reconnaissance faciale, de clustering, de réduction de dimension et de création de bases de données vectorielles pour rendre ces souvenirs photographiques facilement accessibles et interrogeables. Voici un aperçu détaillé de ce travail.
Contexte du Projet
La collection initiale comprenait 37,000 images, dont beaucoup avaient été récupérées d'albums de photos physiques. Ces images couvrent plus d'un siècle d'histoire, et pour beaucoup d'entre elles, il a été nécessaire de rechercher et d'identifier les personnes représentées, en particulier pour les plus anciennes.
Reconnaissance Faciale pour l'Identification
Pour identifier les personnes sur les photos, nous avons utilisé des logiciels de reconnaissance faciale. Ces outils ont permis de détecter et de marquer automatiquement les visages, facilitant ainsi l'organisation des images par individu et par groupe familial.
Clustering et Réduction de Dimension
Techniques Utilisées
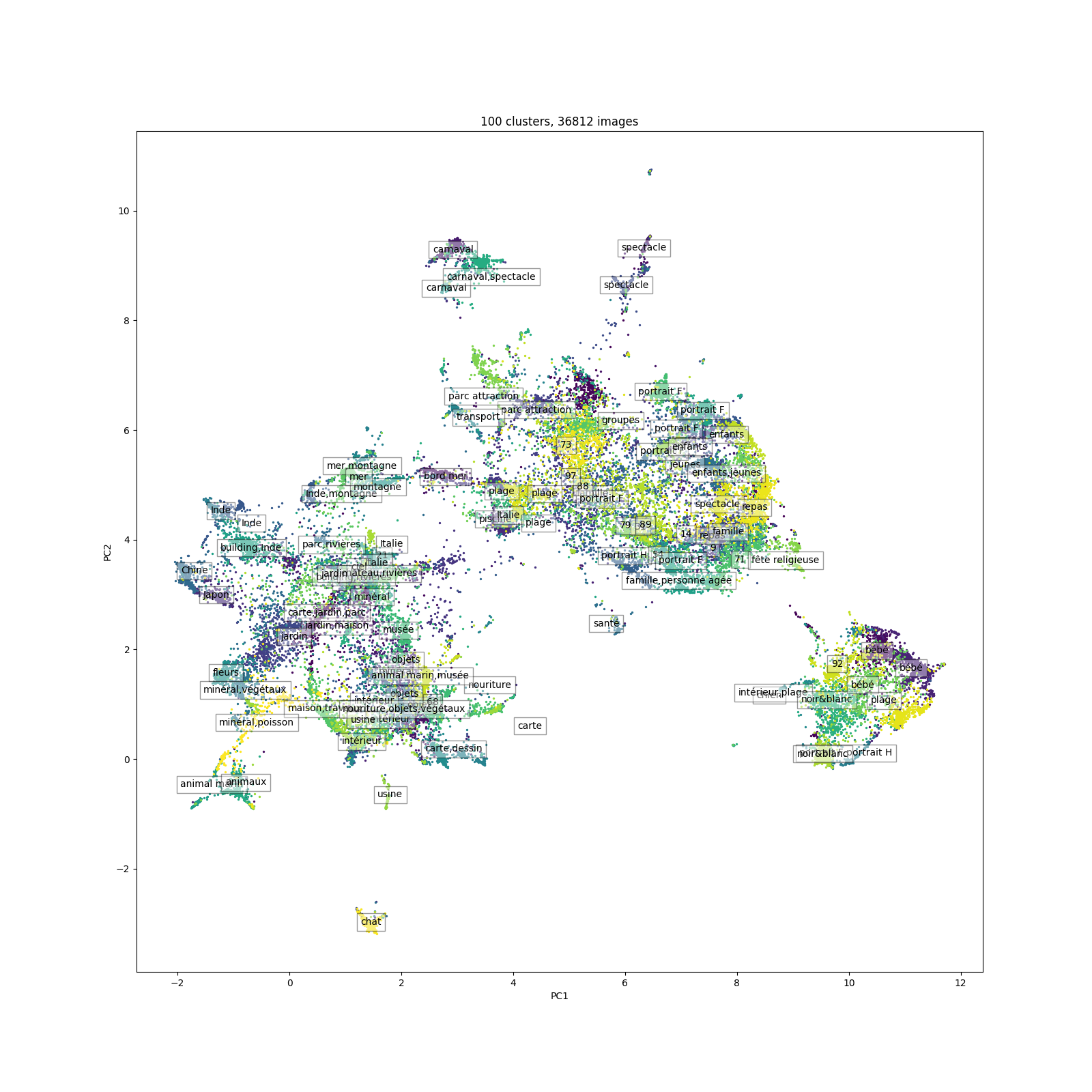
Nous avons appliqué des techniques de clustering pour regrouper les images en fonction de thèmes similaires. Deux méthodes principales ont été utilisées :
- UMAP (Uniform Manifold Approximation and Projection) : Cette technique de réduction de dimension permet de projeter des données de haute dimension en deux ou trois dimensions pour faciliter la visualisation des clusters.
- k-means : Un algorithme de clustering classique qui regroupe les données en k clusters en minimisant la variance au sein de chaque cluster.
Visualisation
Les librairies UMAP et k-means ont été utilisées conjointement pour créer des visualisations intuitives des regroupements. Ces visualisations permettent de voir clairement comment les images se répartissent en différents clusters thématiques.
Création d'Embeddings et Recherche Avancée
Pour chaque image, nous avons créé un embedding, une représentation vectorielle qui capture les caractéristiques essentielles de l'image. Ces embeddings ont été stockés dans une base de données vectorielle, facilitant ainsi des recherches complexes et rapides.
Recherche par Exemples
Grâce aux embeddings, il est possible de réaliser des recherches sophistiquées. Par exemple, une requête telle que "photo avec un enfant au bord de la mer le soleil qui brille un parasol" permet de retrouver instantanément toutes les images correspondant à ces critères. Cela est rendu possible par l'utilisation de la base de données vectorielle qui contient les embeddings des images.
Conclusion
Ce projet démontre comment des technologies avancées de machine learning et de traitement d'images peuvent transformer une vaste collection de photos historiques en une ressource numérique précieuse et facilement accessible. Le clustering, la réduction de dimension et la création d'embeddings ont permis de structurer, visualiser et interroger efficacement les images, ouvrant ainsi de nouvelles possibilités pour la gestion et la préservation du patrimoine photographique.
Nous espérons que cet article vous a offert un aperçu inspirant des défis et des solutions techniques impliqués dans ce projet. Si vous avez des questions ou souhaitez en savoir plus, n'hésitez pas à nous contacter.
------------------------------------------------------------------------------------------------
Découvrez comment nous avons transformé 37,000 images historiques en un trésor numérique 📸
Grâce à des techniques de clustering avancées et à la reconnaissance faciale, nous avons rendu ces souvenirs accessibles et faciles à rechercher 🔍
Plongez dans notre démarche innovante et voyez comment nous utilisons des bases de données vectorielles pour optimiser la recherche d'images précieuses 🌐
#Innovation #DataScience #MachineLearning #PhotoClustering #Fintech #DigitalTransformation #HeritagePreservation #TechForGood #AI #ImageProcessing
